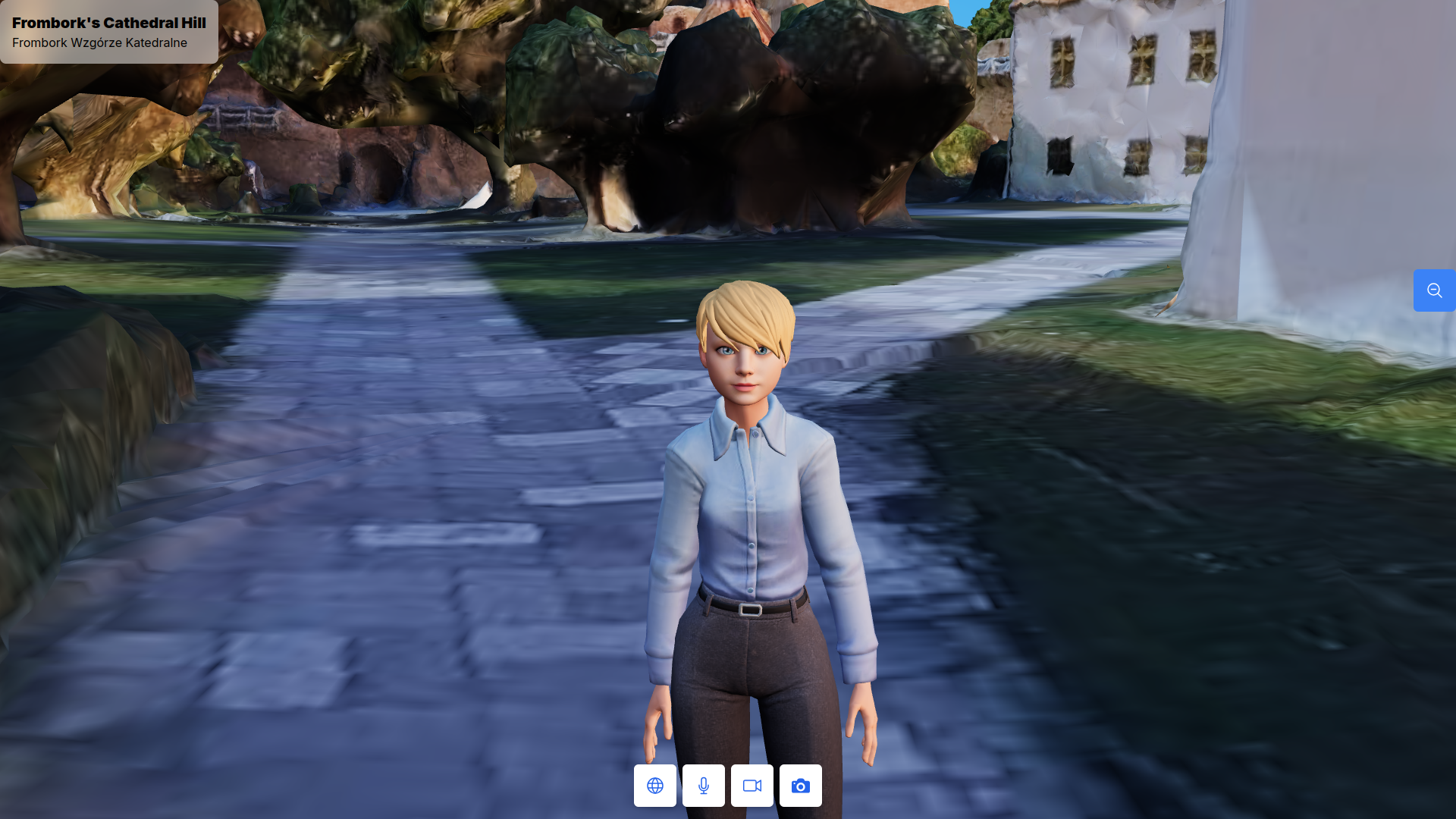
This program creates a fully interactive and lifelike 3D avatar with a range of dynamic features, including:
Display Facial Expressions: The avatar can express emotions like happiness, sadness, anger, surprise, and more.
- Animations: Supports seamless transitions between actions like "Idle," "Walk," and custom animations.
- Lip-Syncing: The avatar's mouth movements synchronize with audio playback for realistic speech.
- Blinking and Winking: The avatar blinks naturally and can wink on command.
- Chat Responsiveness: Reacts to chat messages by animating expressions, syncing speech, and performing actions.
How Is It Made?
Built with cutting-edge web technologies, this program leverages:
- React Three Fiber: A React-based renderer for Three.js, enabling intuitive 3D graphics creation.
- @react-three/drei: Utility tools for tasks like loading models and managing animations with ease.
- Three.js: A robust library for creating stunning 3D visuals.
- Leva: A user-friendly GUI library for real-time interaction and customization.
Key Features
3D Models and Animations:
- Uses
useGLTF to load 3D assets. - Manages animations through
useAnimations for smooth playback and transitions.
Facial Expressions:
- Predefined expressions (e.g., smiling, frowning) use morph targets for lifelike adjustments.
- The
lerpMorphTarget function ensures smooth transitions between expressions.
Lip-Syncing:
- Implements phoneme-to-viseme mapping to synchronize mouth movements with audio in real time.
Blinking and Winking:
- Random blinking is achieved using
setTimeout, while winks are triggered through UI controls.
Chat Integration:
- The
useChat hook processes incoming chat messages, triggering animations, expressions, and lip-syncing.
Interactive UI Controls:
- A Leva-powered control panel allows users to manually adjust animations, facial expressions, and other features.
-
Potential Use Cases
- Virtual Assistants:
Bring a virtual assistant to life with engaging animations and emotional expressions. - Gaming:
Incorporate as a responsive character in interactive games for immersive experiences. - Education & Training:
Develop avatars that explain concepts or guide users in educational tools. - Social Platforms:
Enhance communication in social apps or virtual meeting spaces with engaging 3D avatars. - Entertainment:
Create avatars for virtual storytelling, performances, or interactive experiences. -
In modern web applications, the server plays a critical role in handling requests, processing data, and delivering responses to clients. In this article, we’ll explore the functionality of a server in the context of a specific application that integrates AI-powered text-to-speech, lip-syncing, and image analysis. This server is built using Node.js and Express, and it leverages the OpenAI API for advanced AI capabilities.
Overview of the Server's Role
The server acts as the backbone of the application, handling communication between the frontend (client) and external services like OpenAI. Its primary responsibilities include:
Receiving Requests: The server listens for incoming HTTP requests from the client, such as text messages, audio files, or images.
Processing Data: It processes the data using AI models, such as generating text responses, converting text to speech, or analyzing images.
Generating Responses: The server sends back processed data, such as audio files, lip-sync animations, or AI-generated insights, to the client.
Streaming Data: In some cases, the server streams data (e.g., audio messages) to the client in real-time as it becomes available.
Let’s break down the server’s functionality in detail.
Key Features of the Server
1. Text-to-Speech (TTS) Generation
The server uses OpenAI’s Text-to-Speech API to convert text into natural-sounding audio. Here’s how it works:
The client sends a text message to the server.
The server calls the OpenAI API to generate an audio file (mp3) from the text.
The audio file is saved on the server and sent back to the client.
Example Use Case: A user types a message, and the server responds with an audio file of the AI assistant speaking the response.
2. Lip-Syncing Animation
To make the AI assistant more interactive, the server generates lip-sync animations that match the audio. This involves:
Converting the generated audio file (mp3) to a waveform format (wav).
Using a Python script (generate_lip_sync.py) to analyze the waveform and generate a JSON file containing mouth movement cues.
Sending the JSON file back to the client, which can use it to animate a character’s lips in sync with the audio.
Example Use Case: The AI assistant’s avatar speaks with realistic lip movements, enhancing the user experience.
3. Image Analysis
The server can also analyze images using OpenAI’s GPT-4 Vision API. Here’s the process:
The client uploads an image to the server.
The server sends the image to the OpenAI API, which analyzes its content and generates a textual description.
The server converts the description into speech and lip-sync animations, just like with text messages.
Example Use Case: A user uploads a photo, and the server describes the image in both text and audio formats.
4. Real-Time Streaming with Server-Sent Events (SSE)
To improve responsiveness, the server uses Server-Sent Events (SSE) to stream data to the client in real-time. For example:
When generating multiple audio messages, the server sends each message to the client as soon as it’s ready, rather than waiting for all messages to be processed.
This allows the client to start playing the first audio message while the server continues processing the remaining ones.
Example Use Case: The AI assistant sends a series of messages, and the client plays them sequentially without waiting for the entire batch to be ready.
5. Audio Transcription
The server can transcribe audio files into text using OpenAI’s Whisper API. Here’s how it works:
The client uploads an audio file (mp3).
The server sends the file to the Whisper API, which transcribes it into text.
The transcribed text is sent back to the client.
Example Use Case: A user uploads a voice message, and the server converts it into text for further processing.
Technical Implementation
Technologies Used
Node.js: A JavaScript runtime for building scalable server-side applications.
Express: A web framework for handling HTTP requests and responses.
OpenAI API: Provides access to AI models for text generation, speech synthesis, and image analysis.
FFmpeg: A tool for converting audio files between formats (e.g., mp3 to wav).
Python: Used for generating lip-sync animations from audio files.
Server-Sent Events (SSE): Enables real-time streaming of data to the client.
Code Structure
The server’s code is organized into several key components:
Routes: Define endpoints for handling different types of requests (e.g., /chat, /vision, /upload-audio).
Middleware: Handles tasks like file uploads (multer) and CORS configuration.
Utility Functions: Perform specific tasks, such as converting text to speech, generating lip-sync animations, and reading JSON files.
Error Handling: Ensures that errors are logged and appropriate responses are sent to the client.
-
Example Workflow
Here’s a step-by-step example of how the server processes a chat message:
The client sends a text message to the /chat endpoint.
The server forwards the message to the OpenAI API, which generates a response.
The server converts the response into speech using the TTS API.
The server generates lip-sync animations for the audio.
The server streams the audio and lip-sync data back to the client in real-time.
Benefits of the Server’s Design
Scalability: The server is designed to handle multiple requests simultaneously, making it suitable for applications with many users.
Real-Time Interaction: By using SSE, the server provides a seamless and responsive user experience.
Modularity: The server’s code is modular, making it easy to add new features or modify existing ones.
AI Integration: The integration with OpenAI’s APIs enables advanced capabilities like natural language processing, speech synthesis, and image analysis.
Challenges and Considerations
Performance: Generating audio and lip-sync animations can be computationally expensive. Optimizing these processes is crucial for maintaining performance.
Error Handling: The server must handle errors gracefully, such as API failures or invalid input from the client.
Security: Protecting sensitive data (e.g., API keys) and validating user input are essential for maintaining a secure application.
Conclusion
The server is the heart of the application, enabling advanced features like text-to-speech, lip-syncing, and image analysis. By leveraging AI and real-time streaming, it provides a rich and interactive experience for users. Whether you’re building a virtual assistant, a chatbot, or an image analysis tool, understanding the server’s role is key to creating a successful application.
With the right design and optimization, the server can handle complex tasks efficiently, ensuring a smooth and engaging user experience.


{kind=link}
{kind=link}





